Your cart is currently empty!
Brave New World of Photography and AI
Dear friend,
We are currently undergoing a phenomenally exciting time in photography– the marriage of (human) photographers and AI (artificial intelligence):
What is the future of pictures and images?

“A picture used to be a sum of additions. In my case, a picture is a sum of destructions.” – Picasso
A lot is going on. To get caught up, I recommend reading the lecture slides from the Stanford Computer Vision Course.

Some concepts which are fascinating to me:
- Segmentation masks
- Edge detection
- ‘Whitened’ images
- Color ‘jittering’
- Semantic and Instance segmentation
- 3D Object detection
- 3D Bounding Boxes
How can all this AI stuff help us?







Ultimately, I like this simple idea:
The future of humanity is that we will become ‘centaurs‘ — half-man, half machine.
So simply in photography– this is what I am interested in:
How can we use computer vision (how computers see images, objects, and the real world) to augment (increase) our own human vision– to see the world more vividly, and to ultimately make better photos?
Imagine

This is one of my visions:
Imagine a world in which your phone could see the world like the image above. You can click a toggle switch, and suddenly you see the world ‘augmented’ with these little dots, lines, to outline human skeletons. This would help you better see the poses and body language of your subject– to hopefully make better pictures.
Or imagine you are photographing your friend (or shooting video), and you can see them abstracted as a skeleton — to better see their poses:

Now imagine when this can all be easily automated– in real-time (or perhaps afterwards when you’re looking at pictures in your phone or computer):

A sneak peek of how AI ‘sees’ human poses (with heat maps). Learn more on the MIT Deep Learning Course:

The future is already here

Jonathan Hui did a pretty good overview of how this ‘image segmentation’ technology works (I also reading the scholarly paper on ‘MASK R CNN [PDF]‘.
The basic idea is this:
The program will automatically create ‘bounding boxes‘ around the subjects in the frame, then create ‘segmentation masks’, and do both:
- Semantic segmentation (What is in the scene? Is it a person or a dog?)
- Instance segmentation (If there are 5 people in a scene, how can we create separate segmentation masks around each person)?

A free tool we can play around with is the ‘Pixel Annotation Tool‘ — to create customs masks for our images:


Computer Vision and Video

When I first saw the above GIF of a man doing parkour (then computer vision abstracting him into a simple 3D-shape) my mind was blown.
Another vision I have:
Imagine if you see your friend breakdancing or doing something interesting, and you take out your iPhone. You turn it into ‘Augmented’ mode, hold up your camera, and then you can (in real-time) see your friend suddenly augmented into a 3D model.
It ain’t so farfetched. Look at some of this insane technology that exists RIGHT NOW!
For example, look at this real-time ‘pose estimation’ framework:

You can play with the PoseNet Browser Demo Here >. Some examples:




Also see the PoseNet Code on GitHub >
For more inspiration, check out Dan Oved– doing lots of interesting cross-pollination between eye-tracking, machine vision, and art >
Also check out TensorFlow.JS — to experiment with machine learning on your browser >
Self-driving cars, machine vision, AI, and photography

Andrej Karpathy is probably the most interesting person in AI, computer vision, etc to follow (@karpathy on Twitter). See his ‘TRAIN AI 2.0′ PDF presentation‘ or watch his Video Presentation >

The future is already here with autopilot and self-driving cars, as you can see in this (2016 video) of Telsa’s Autopilot in Action:
Autopilot Full Self-Driving Hardware (Neighborhood Long) from Tesla, Inc on Vimeo.
Anyways I’m getting off-topic, but what Andrej Karpathy is doing is fascinating — combining AI, machine vision, and self-driving cars (practical idea) — while baking in the philosophy of it all (see his Ph.D. PDF paper here).
I actually believe that if you’re interested in computer vision, best to see the ways that industry-Tesla, etc are able to actually integrate machine learning, AI, and computer vision in the ‘real world’.



Hand-made image annotation

Anyways what I learned from Andrej is that as humans, it is essential for us to learn how to annotate our own images– to figure out what is truly significant in our pictures.
For example to analyze the above picture, I think it is a very powerful and significant photo. Why?
First of all, It is a commentary on American society. For many Americans (and people in the world), the dream is to have a really cool, fast car (sports car). The Ford Mustang is the symbol of freedom, being bold, and being a badass. For example look at this Shelby advertisement ‘POWER that’ll SLAM YOUR SENSES’ (the idea that we must buy a mustang, in order to become more masculine):

Then see the funny juxtaposition (contrast) between this badass Mustang and the little hand-drawn image below:

Close-up:

Then see the triangle composition between all these elements in the frame:

Also if we add Gaussian Blur, you can see the color tones of the picture: soft pastel blue in background, bold mustang (bright blue against black), and red American flag in top-right, and white paper in bottom-center of frame:

With the color boxes added in:

With the background simplified:

Anyways I’m getting off-topic — but this is what I think:
The future of machine vision, AI will help us identify what is the contents of the picture (what is it a photo of), but it will not be able to tell us the philosophical consequences/commentary on images.
Social Commentary

For example using the Google Vision API, let us insert this picture I photographed in Chicago, of a black girl with a (white) Cinderella barbie doll. The Google Vision API (AI) can determine that the girl is very happy, by ‘feature mapping’ her face:

When labeling the picture, the AI puts interesting labels like, ‘child, toddler, fun, product’:

Google can also figure out that it was shot on Kodak Portra 400 (by cross-referencing my blog), and it knows it is a ‘street photograph’:
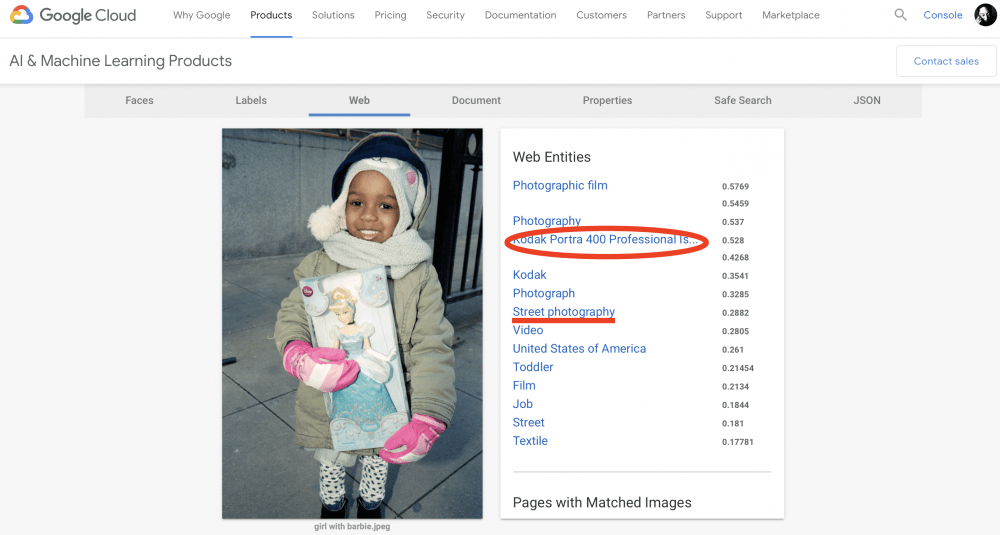
Anyways, Google, AI, and computer vision can do all this. But it cannot do this:
Make the social commentary of having a little black girl so excited having a (white) barbie doll.
Perhaps my social commentary is this: “It is sad that a lot of young black girls would possibly prefer to own a white barbie doll, instead of a black barbie doll” (this is also tricky to say, because who knows if she already owns thousands of black barbies at home). Thus every picture you shoot is embedded with your own soul, your own pre-conceived notions, and your own opinion.
Conclusion

I’m still trying to figure out all this. At the moment, my primary interests include the intersection of photography, AI, visual art, ethics, and philosophy.
Some basic ideas:
- It seems that the future of photography will be more based on creating abstract images– that AI, machines cannot interpret or even create.
- Artistic ‘style’ will always first be innovated and created by humans, and then later ‘taught’ to machines. Thus, you should innovate in your artistry (Study Wassily Kandinsky, Picasso, Claude Monet, etc).
- Utilize AI in your creative tools to augment and empower you as a photographer and visual artist. Learn how to see like a machine, and recognize that AI is good for us as photographers. Use AI to analyze your photos (after the fact), and ultimately follow your gut when you’re shooting pictures.
- No matter how good pictures we make– we will always seek to impress other human beings, not machines. Thus if you want to get honest feedback on your photos, upload it to ARSBETA.COM.
And ultimately– photography is an art-form, and a philosophical pursuit.
Ask yourself the simple question:
What do your photos reveal about your soul?
ERIC
Machine Learning
Brave new world of photography:
- Use AI, Neural Networks, and Deep Learning to Judge Your Photography Compositions
- How Can AI (Artificial Intelligence) Help You Analyze Your Photos?
- What Can AI (and AlphaGo) Teach us About Being Human?
- Composition and Machine Learning: Bounding Boxes for Photographers
- How Photographers Can See Like Machines
- Why AI (Artificial Intelligence) is Good for Photographers!